
WhatsApp een scriptiebegeleider
0614592593
Geschreven door: Mirjam de Winter
Laatst geüpdatet op: 27 augustus 2025
De meeste studenten hebben tijdens hun opleiding wel met SPSS leren werken. Bij veel studenten is die kennis echter weggezakt op het moment dat ze die het hardste nodig hebben: tijdens hun afstuderen. Daarom geven we op deze pagina SPSS tips. We hebben volgende vijf basisstappen (de belangrijkste SPSS tips) voor je op een rij gezet. Wanneer je deze stappen helemaal volgt dan heb je de basis-analyses uitgevoerd. Succes!

Stap 1: Transformeer je vragenlijst in een codeboek
Een codeboek is een overzicht van 1 of 2 A4 (afhankelijk van de omvang van je vragenlijst) waarbij je de antwoorden van de vragenlijst codes geeft en aangeeft wat die codes betekenen. Het is gebruikelijk om de code 0 alleen te gebruiken als er sprake is van een dummy variabele; in alle andere gevallen laat je de codering gewoon beginnen bij 1.
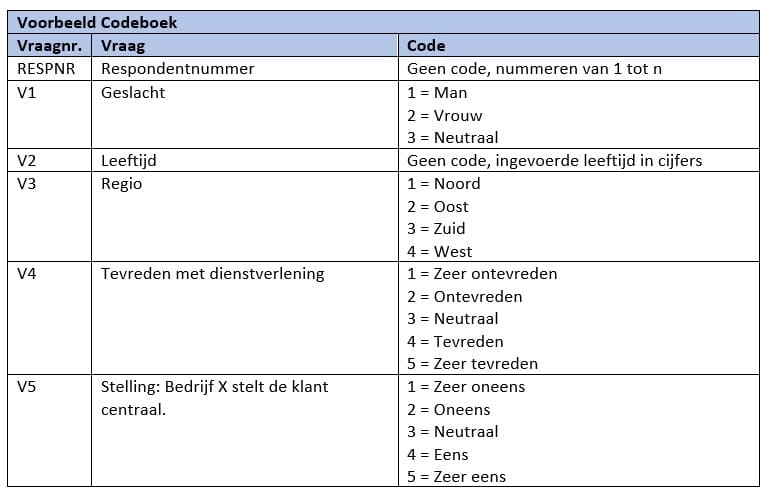
Stap 2: Verwerk het codeboek in SPSS: Variable View
SPSS heeft twee basisschermen: Data View en Variable View. Je start je proces altijd in Variable View (je kan onderaan het scherm switchen tussen Data View en Variable View). In Variable View kan je het codeboek invoeren. Daarbij kan je achtereenvolgens de volgende cellen invullen:
Stap 3: Voer je data in en controleer voor ontbrekende data
Nu ben je klaar om je data in te voeren. Je gaat daarvoor naar het scherm Data View. In de kolommen staan alle variabelen zoals je die hebt aangemaakt. Iedere rij vertegenwoordigt één respondent. Gebruik voor ontbrekende data (Missing values) de code zoals je die hebt aangegeven in het codeboek (bijvoorbeeld -99). Via ‘Data’- ‘Define Variable Properties’ (in het scherm Variable View) kan je aanvinken welke waarden ‘Missing’ zijn.
Wanneer je de data online verzameld hebt, kan je die het beste rechtstreeks importeren in SPSS.
SPSS tip: Op YouTube zijn veel filmpjes te vinden over hoe je dit het beste kunt doen.
Stap 4: Beschrijvende statistiek
De term ‘beschrijvende statistiek’ zegt het al: je start je data-analyse met het beschrijven van je data. Dat beschrijven gaat meestal op twee manieren: 1) via frequentietabellen en 2) via centrum- en spreidingsmaten. Beide manieren worden hier besproken.
In een frequentietabel is te zien hoe vaak iedere waarde voorkomt per variabele. In SPSS krijg je een frequentietabel door de volgende stappen uit te voeren:
Centrummaten (zoals het gemiddelde) en spreidingsmaten (zoals de standaarddeviatie) zijn een andere manier om de data te beschrijven. Je verkrijgt de centrum- en spreidingsmaten in SPSS via de volgende stappen:
Stap 5: Kruistabellen
Nadat je jouw data hebt beschreven, ga je die nader onderzoeken. Een eenvoudige manier om op zoek te gaan naar patronen in je data is door gebruik te maken van kruistabellen. In een kruistabel zet je twee variabelen tegen elkaar af, bijvoorbeeld ‘Tevreden met dienstverlening’ en ‘Geslacht’. In dat voorbeeld denk je dat de tevredenheid van de dienstverlening wel eens af zou kunnen hangen van het geslacht. ‘Tevredenheid met dienstverlening’ is in dat geval de afhankelijke variabele en ‘Geslacht’ de onafhankelijke variabele. Je maakt een kruistabel met SPSS via de volgende stappen:
Stel dat je in bovenstaand voorstel een verschil vindt tussen mannen en vrouwen in relatie tot de variabele ‘Tevredenheid met dienstverlening’. In dat geval wil je graag onderzoek of dat verschil significant is. Dat doe je door middel van een chikwadraattoets. In SPSS volg je de volgende stappen:
Het maken van een kruistabel kan alleen wanneer je data in categorieën presenteert. Wanneer je bijvoorbeeld leeftijd als absoluut getal hebt gevraagd in je enquête, kan je daar dus niet direct een kruistabel van maken. Je moet de data dan eerst hercoderen. Dat doe je als volgt:
Goed gedaan! Je hebt nu de basis van SPSS in kaart! Veelal is het nodig om je data vervolgens dieper te analyseren (vergeet niet om altijd voorafgaand aan het uitvoeren van deze analyses de assumpties te checken). Hieronder geven we je kort een aantal opties in SPSS:

Topscriptie wenst je veel succes bij de verwerking en analyse van jouw kwantitatieve data middels deze SPSS tips. Kom je er niet helemaal uit en heb je hulp nodig? We hebben verschillende SPSS begeleiders die je graag helpen.
Laat ons je helpen bij je studie. Vraag direct gratis en vrijblijvend advies aan.
WhatsApp een scriptiebegeleider
0614592593
Statistiek: assumpties
Alle onderwerpen in
Scriptietips
Een intakegesprek is altijd geheel vrijblijvend, we geven je graag meer persoonlijke informatie en een advies op maat, zodat je vooraf een goed beeld hebt bij wat we voor jou kunnen betekenen.